Data Preparation & Feature Generation with Sparkflows
- Sparkflows
- Nov 3, 2016
- 2 min read

One of the major strong points of Sparkflows is Data Preparation and Feature Generation. As Sparkflows provides a workflow interface with very powerful nodes combined with interactive execution, data preparation becomes very easy.
Sparkflows greatly enables it in the following ways:
Provides an easy way to read data from various sources (HIVE, HDFS, HBase, Solr, RDBMS) and formats (CSV, TSV, Parquet, Avro, Binary, PDF etc.)
Provides a number of nodes for doing ETL. These include Join, DateTimeFieldExtract, Filter etc. The full list is available here : http://www.sparkflows.io/nodes-dataset-etl-save
Provides a number of complex feature generation nodes. These include Imputer, Tokenizer, TF, IDF, Stop Word Remover etc.
Provides an easy way to save the results to various stores (HDFS/HIVE, HBase, Solr, RDBMS) in various formats.
Above all, Sparkflows provides a way to interactively execute each Node and immediately view the results. Hence, its easy to build the workflow along.
Simple but interesting example:
Sparkflows has a number of out of the box workflows which apply the above features. We tried a simple end to end scenario to ensure that we can read data, transform it with some complexity, and then be able to read it back.
Took a dataset with a string column
Tokenized the string column to generate a new tokenized column. It is of Array type.
Saved the dataset into a directory in Parquet format
Defined a new dataset onto the directory
Used the dataset in a workflow
The workflow was seamlessly able to read in the dataset with the tokenized column and able to process it.
This means that all the complex features generated by the library of available nodes in Sparkflows, can be easily used for further steps with Parquet format.
Workflow for tokenizing a column and saving as Parquet file on HDFS
This workflow creates a new column which is an array of strings.

Dataset created seamlessly from the directory in which it was saved
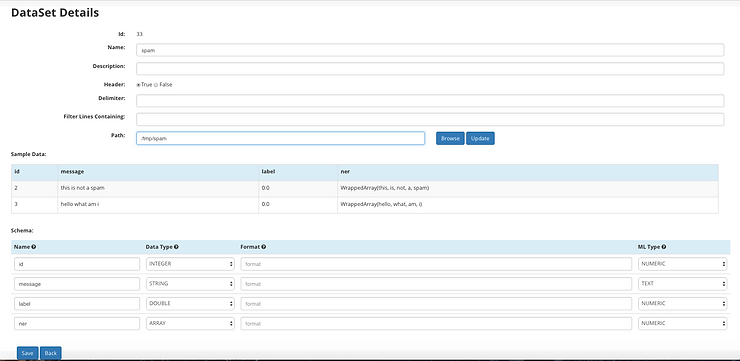
The Parquet directory read back into a workflow with the Dataset Node and results displayed





Comments