
Collaborative Self-Serve Advanced
Analytics with Sparkflows + AWS
Perform Data Analytics, Data Exploration, and build ML models
and Data Engineering in minutes using the 450+ Processors in Sparkflows

Sparkflows is deeply integrated with and certified on AWS. It can be installed on an EC2 machine and can run in standalone more or submit the jobs to EMR or AWS Glue. It can process data from S3, Redshift, Kinesis etc.
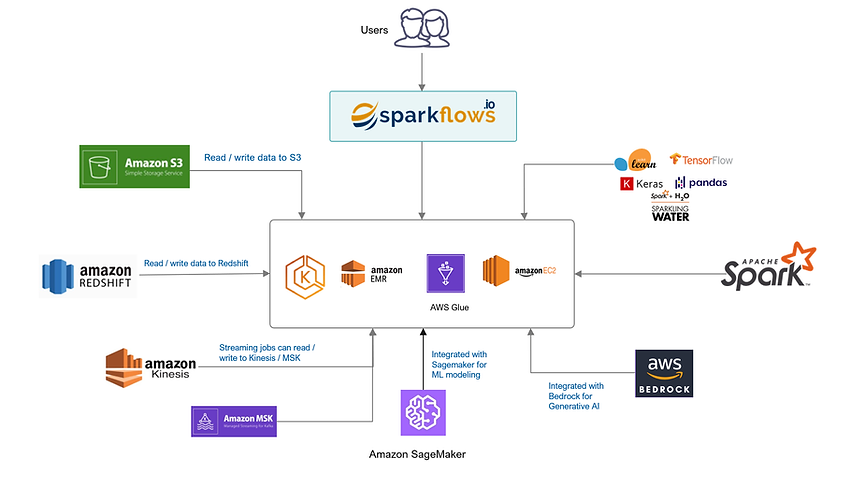

Build and Run Analytics and ML jobs on EMR or standalone machines.
Seamlessly read files from
S3 and process them.
Send data to and build ML
models on Sagemaker
Read and Write data to Redshift.
Read and process streaming
data from Apache Kafka and Kinesis.
Results include data in
Charts, Tables, Text etc.

Integration with EMR
Sparkflows can be easily installed on an AWS EMR Cluster. Sparkflows can be installed on the master node of an EMR cluster. It would then submit the jobs to the EMR cluster.

Sparkflows can submit the Analytical Jobs to be run onto AWS Glue. The results and visualizations are displayed back in Sparkflows.
Integration with Glue

Integration with Redshift
Sparkflows is fully integrated with Redshift. Sparkflows has processors for reading from and writing to Redshift. They include:
Read Redshift AWS
Write Redshift AWS

Integration with S3
Sparkflows allows you to access your files on S3. The jobs run by Sparkflows can read from and write to files on S3. The files can be in various file formats including CSV, JSON, Parquet, Avro etc. Sparkflows also allows you to browse your files on S3.
Integration with Sagemaker

Amazon Sagemaker
Sparkflows is fully integrated with AWS SageMaker. Sparkflows provides a number of processors for doing model building with SageMaker. These include :
LinearLearnerBinaryClassifier
LinearLearnerRegressor
PCASageMakerEstimator
SaveSageMaker
KMeansSageMakerEstimator
XGBoostSageMakerEstimator
LDASageMakerEstimator
Benefits of Sparkflows on AWS
Find quick value with Sparkflows and AWS
Enable Business Analysts
Enable Business Analysts to find quick value with AWS clusters.
Self Serve Advanced Analytics
Enable users to do analytics and Machine Learning in minutes.
Enable 10x more to build
Data Science use cases.
10x More Users
Makes it easy to build, maintain
and execute
No code and low code platform
Return on Investment (ROI)
Solve your data science use cases 10x faster.